안녕하세요. 저자 김임용입니다.
책을 출판하고, 1년이 지나지도 않았는데 R의 생태계에도 다양한 변화가 생겼습니다.
책을 집필할 경우만 하더라도 3.6.3 버전으로 별다른 이슈가 없었으나 2022년 4월을 기준으로 4.2버전까지 나오면서 데이터 타입 인식 및 각종 패키지 호환 문제 등이 발생하고 있습니다.
데이터 타입 문제
특히, 가장 빈번히 발생하는 오류는 "Chapter 6. 분류 및 군집분석"에서 다양한 분류 모델을 이용해 학습시킬 때 발생합니다. 대표적인 오류는 아래와 같습니다.
[로지스틱 회귀분석 실행 시 오류]
> g_glm <- glm(gender~wing_length+tail_length, data=g, family=binomial)
Error in eval(family$initialize) :
y 값들은 반드시 0 이상 1 이하이어야 합니다
[랜덤포레스트 실행 시 오류]
> c_rf <- randomForest(breeds ~., data = c_train, type = "class")
Error in y - ymean : non-numeric argument to binary operator
In addition: Warning messages:
1: In randomForest.default(m, y, ...) :
The response has five or fewer unique values. Are you sure you want to do regression?
2: In mean.default(y) :
인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다
[Confusion Matrix 실행 시 오류]
> confusionMatrix(c_test$pred5, c_test$breeds)
Error in confusionMatrix.default(c_test$pred5, c_test$breeds) :
The data must contain some levels that overlap the reference.
위와 같은 문제가 발생하는 이유는 분류모델 문제가 아닌 데이터를 불러올 때 타입 문제로 인해 발생한 것입니다.
기존에 학습 및 테스트용 데이터를 불러오는 코드는 아래와 같았습니다.
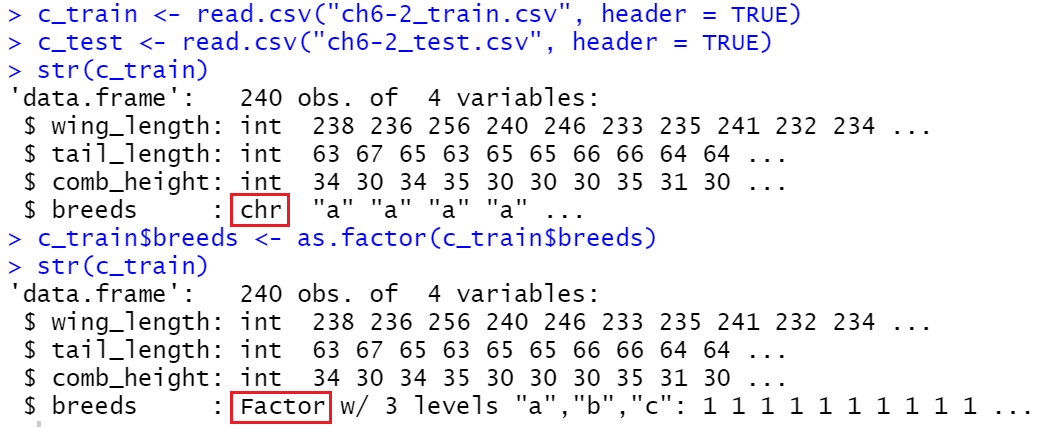
c_train <- read.csv("ch6-2_train.csv", header = TRUE)
c_test <- read.csv("ch6-2_test.csv", header = TRUE)
R 3.6.3 버전에서는 위와 같이 데이터를 불러올 시 문자로 값이 이뤄진 gender나 breeds 열이 Factor(Categorical Data, 레벨 개념 존재) 타입으로 지정되었으나 이후 4점 대 버전에서는 단순한 문자 타입인 Charactor 타입으로 지정되면서 각종 분류모델(Classification Model)과 Confusion Matrix를 그릴 때 위와 같은 오류가 발생합니다. 이를 해결하기 위해서는 데이터를 불러올 때 string 형태 데이터를 Factor 타입으로 지정하라는 옵션을 아래와 같이 추가하면 됩니다.
c_train <- read.csv("ch6-2_train.csv", header = TRUE, stringsAsFactors = TRUE)
c_test <- read.csv("ch6-2_test.csv", header = TRUE, stringsAsFactors = TRUE)
아니면 기존과 동일하게 데이터를 불러온 뒤 as.factor() 함수를 이용해 Factor 타입으로 변환해도 됩니다.
c_train <- read.csv("ch6-2_train.csv", header = TRUE)
c_test <- read.csv("ch6-2_test.csv", header = TRUE)
c_train$breeds <- as.factor(c_train$breeds)
c_test$breeds <- as.factor(c_test$breeds)
패키지 호환 문제
이러한 데이터 타입의 이슈 이외에도 각종 패키지가 최신 버전으로 업데이트 되면서 과거의 R 버전을 지원하지 않는 문제도 발생함을 확인하였습니다.
특히 caret, randomForest 패키지가 더 이상 과거의 R 버전을 지원하지 않는 문제가 발생하고 있으며 이를 위해서는 R 버전을 올리거나 과거의 패키지 버전을 설치하는 선택이 필요합니다. 앞서 설명드린 것처럼 R 버전을 올릴 경우 위에 언급한 문자열 데이터 타입을 Factor 타입이 아닌 단순히 Charactor 타입으로 인식하는 문제가 발생합니다.
만약 과거의 R 버전을 그대로 사용하고, 패키지를 특정 버전으로 낮춰서 사용하려면 아래의 제 포스팅을 참고하시기 바랍니다.
https://datawithnosense.tistory.com/43?category=812527
(R) 특정 버전 패키지 설치하기
R을 이용하다보면 지속적인 버전 업이 되면서 특정 패키지가 과거의 R 버전을 지원하지 않는 경우가 생기거나 반대로 패키지가 R 버전 업을 따라가지 못하고, 그대로 남게되는 경우가 발생합니
datawithnosense.tistory.com
다만 이러할 경우 의존되는 다른 패키지의 호환성 문제가 발생할 우려가 있습니다.
만약 R 버전을 4점 대로 올릴 경우 다른 Chapter는 문제가 없으나 "Chapter 8. 텍스트 마이닝" 진행이 안됨을 확인했습니다. 이유는 한글 자연어 분석 패키지인 KoNLP 인스톨이 되지 않는 문제로 해당 패키지는 이미 업데이트가 중단되어서 과거 버전을 설치하고 있는데, 의존되는 패키지와 Rtools 버전 등 여러 패키지 간의 호환성 문제로 설치가 되지 않습니다.
따라서 R 버전별로 내용을 정리하자면 아래와 같습니다.
● R 3.6.3 : 패키지 설치 시 과거 버전으로 지정하면 문제없이 전 Chapter 진행 가능
● R 4.1.3 : 문자열 데이터 타입 인식 문제 있음(코드 수정으로 대응), "Chapter 8. 텍스트 마이닝" 진행 불가
지속적으로 프로그램과 패키지가 업그레이드 또는 업그레이드가 중단 됨에 따라 발생하는 문제지만 독자분들께 불편을 드려 죄송하고, 양해 부탁드립니다.
이외의 추가적인 오류나 질문은 언제든지 환영하오니 댓글을 통해 남겨주시기 바랍니다.
감사합니다.
'(책) 현바데분 with R' 카테고리의 다른 글
| (현바데분withR) PostgreSQL DB 연결용 iris 테이블 생성 방법 (2) | 2022.09.05 |
|---|---|
| (현바데분withR) 책 교정 및 보충사항 (15) | 2021.09.23 |
| (현바데분withR) 패키지 리스트 (0) | 2021.09.21 |
| (현바데분withR) Q&A (41) | 2021.09.21 |
| 현장에서 바로써먹는 데이터 분석 with R (0) | 2021.08.03 |